Hi, nerds !
Let’s say that you (like me) have just learned basics of probabilistic programming – you have some ideas why it’s usefull and you tried some things using existing libraries.
Now you wonder – how the hell does it actually work ? Let’s go deeper !
I am writing this primarily to myself to structure my knowledge. Goal is to test it on an example and also kill several buzzwords and replace them with intuition your grandma could understand
- Monte Carlo
- Markov Chain
- Monte Carlo Markov Chain (MCMC)
- Metropolis-Hastings
The problem
Let’s say you have described phenomenon with fancy model using probability distributions. It might be movement of stock, result of portofolio after some time, weather or something else.
We will start with something very simple – one Gaussian
This might represent something natural – something where extremes are less and less likely – height or weight or person etc
You might have some examples of data and you will not know what is the “generator” distribution as it will be nature, god or crazy people on stock market. At this point (depending on what’s your goal) you might want to know values of variables/hyperparameters of your model, which best describes the data you have.
Let’s generate some data – mean is 5 and variance is 1
1 2 | |

Now, we want to find values of \(\mu\) and \(\sigma^2\)
Of course we could simply compute mean and standard deviation from the data we have, but in reality, the model will be much more complex than one normal distribution
To make it even more simple, let’s forget about \(\sigma^2\) and say that we know it (it’s 1)
Probabilistic programming is using bayes theorem to find most probable value of our hyperparameters (\(\theta\)) with
- Some example data we are trying to describe by model – \(X\)
- Some prior belief what those hyperparameters might be \(P(\theta)\)
This equation will not give us single value of \(\mu\), but probability distribution – values of \(\mu\) which when used as mean of gaussian better describe data we have and at the same time are more likely given our prior belief what those values should be, will be more likely
So once again – our goal is not to approximate distribution of \(X\) but rather approximate posterior distribution of \(\theta\)(from which we care only about \(\mu\) for simplicity)
So let’s try to compute it
likelyhood – \(P(X|\theta)\) – if the parameter would be like that, how does it explain the data we have.
1 | |
prior – \(P(\theta)\) – is such parameter likely given our prior belief about what our variable might be. Easy to compute
1 | |
evidence or normalization factor – \(P(X)\) – is probability, that data we have was generated by the model (all possible parameters \(\theta\)). This one is tricky as we would need to evaluate all possible distributions (of same class). This is equivalent to computing integral \(\int {P(x,\theta)\delta\theta}\) This is possible for simple distributions, but with more complex with more variables it would be extremely hard – we need a trick around that

Metropolis Hastings
Metropolis-Hastings is algorithm able to indirectly sample from posterior distribution. It works by creating “shadow” distribution which is proportional to distribution we want to sample from. This “shadow” distribution becomes more and more like the target distribution as we sample from it.
The algorithm is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
The condition is not that strict, new value will be used in proportion to new_fit/old_fit – even if new value is worse than old, it will be used some of the time – this ensures it will not stuck in local maximum
We choose “better fitting” value relatively more often than the “worse fitting” value
If we put posteriors of both “good and bad” suggestions to proportion, we can see, that it’s the same whether we use posterios (normalized by P(x)P(x)) or not. This means that that the “shadow” distribution is proportional to posterior distribution we are looking for. Why ? Because good vs bad values in shadow distribution are as likely as good vs bad values in posterior distribution (see the equation) and we made sure, that good fits are more likely than bad fits
Let’s build it 🙂
We are going to sample from shadow distribution and remember each value so we can later visualize it.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | |
If we plot the trace, we will see that it converges to 5. The steps until it happens is called burn-in period
1 | |
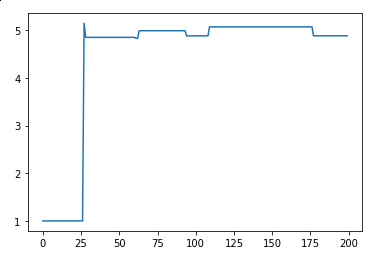
It would be even more clear if we animate it
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | |
- Left-most column shows prior (it’s static) and current (best) and proposed value (proposed mean of distribution of \(\mu\))
- Middle column shows data we have (blue) and proposed gaussian describing that
- Right column visualizes the trace and displays mean – the mean converges to real value of \(\mu\) (5)
Now let’s just save it as .gif file, wait one lifetime until it happens and see
1 | |
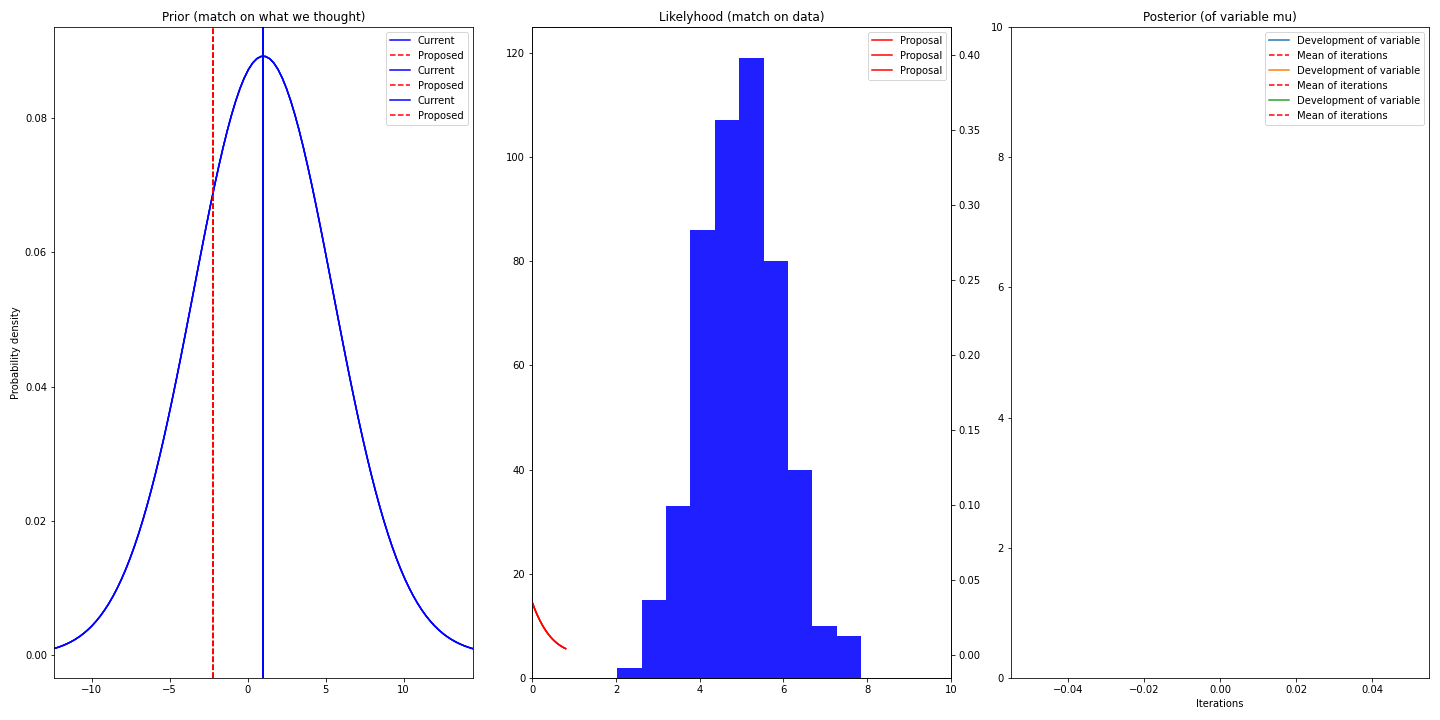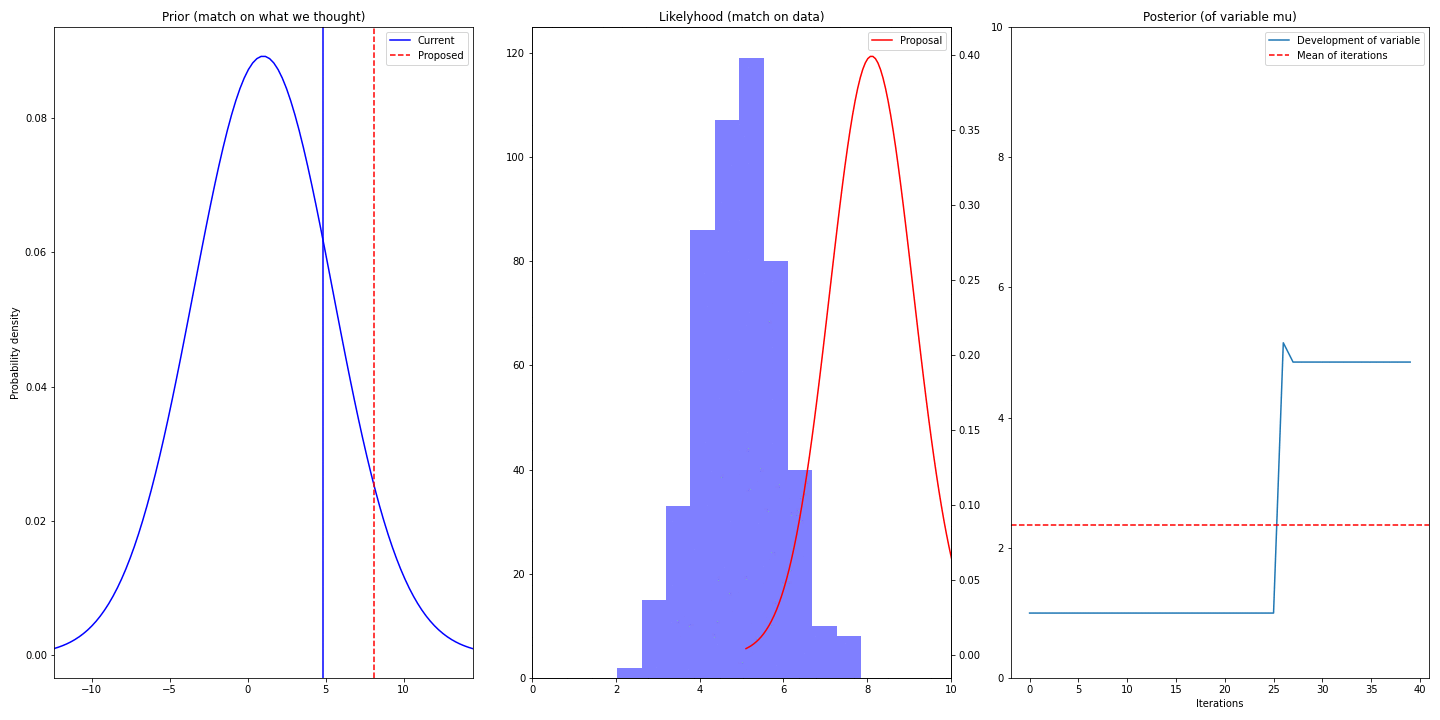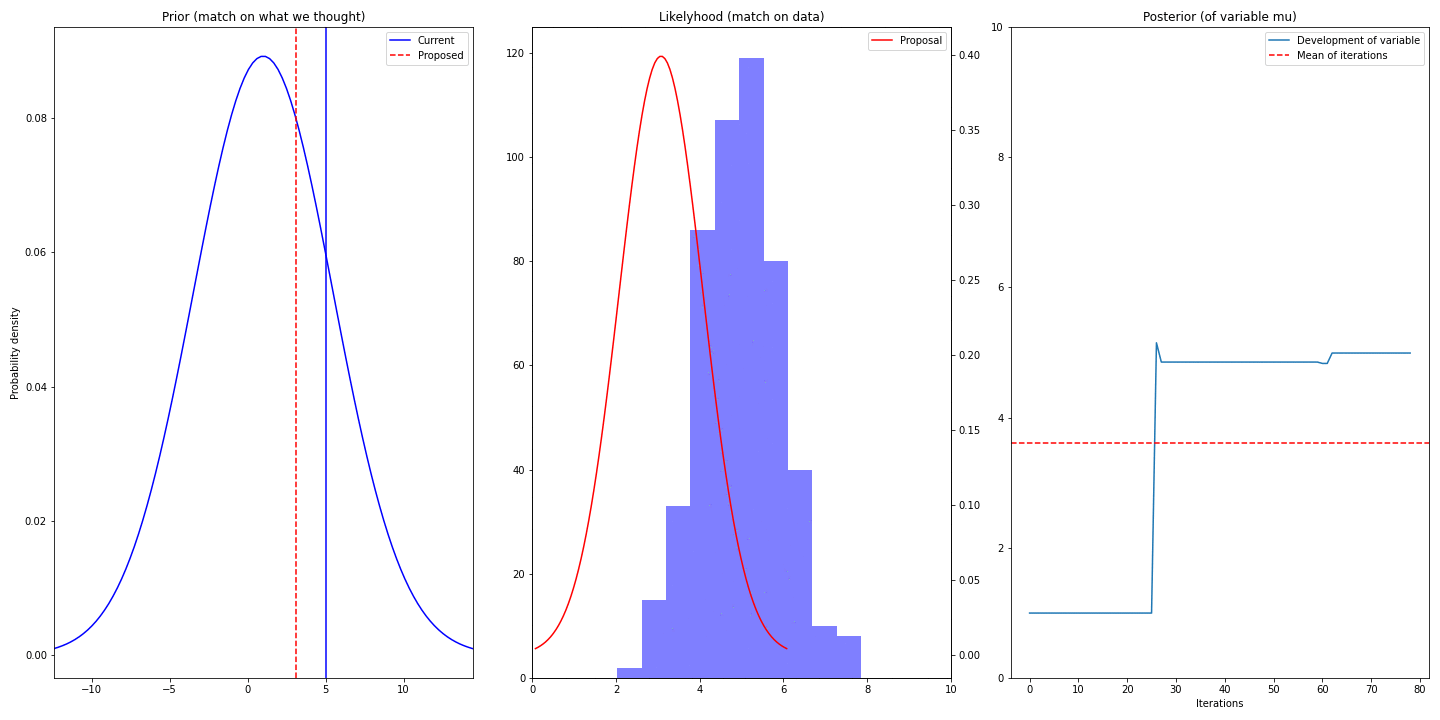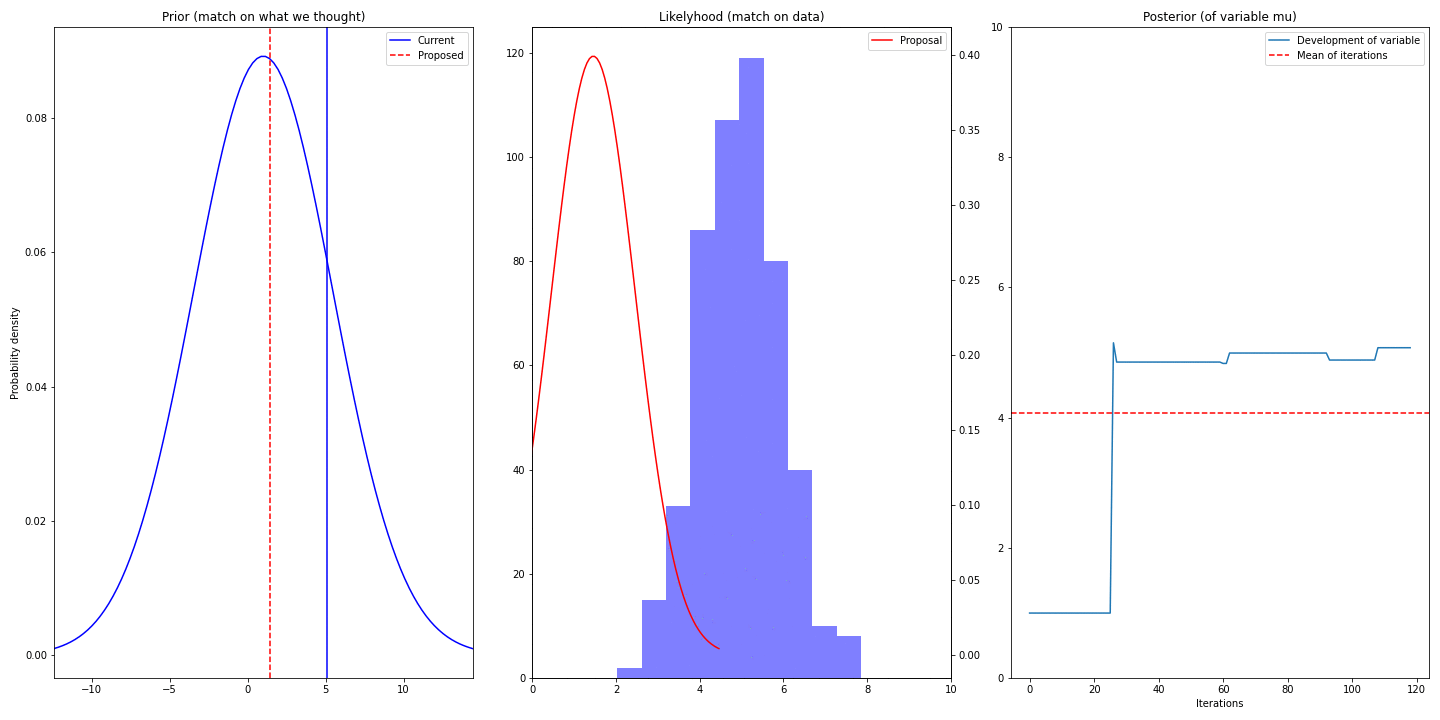
You can see, that we are struggling for some time (burn-in period) before converging. It’s because we have chosen bad value of our prior – we have chosen 1 and by that making the truth value 5 an unlikely sample. So choice of prior might speedup/slowdown the convergence (unless the right values has probability of 0)
Let’s kill the buzzwords:
- Monte Carlo – more or less stupid brute force over some sample space to find what we are looking for
- Markov Chain – random walk – step \(t_n\) depends only on \(t_{n-1}\) fancy people call this "markov blanket" Where is markov chain hidden in Metropolis-Hastings ? In shadow distribution ! Based on current value, we will draw new one, which will either be next value or not
- Monte Carlo Markov Chain – combination of the two above for example using Metropolis-Hastings
- Metropolis Hastings – specific implementation of MCMC (not the smartest)
If you managed to read so far, I would like to congratulate – you can now explain MCMC to your grandma.
If you found any mistakes or have any suggestions about the article, please let me know in comments